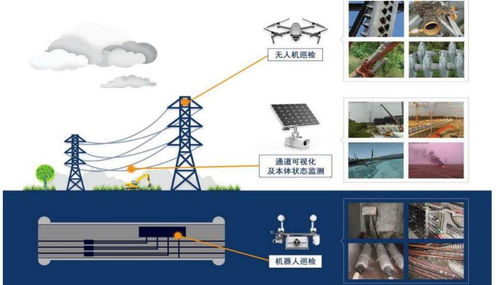
在当今人工智能技术飞速发展的浪潮中,强化学习(Reinforcement Learning, RL)作为机器学习的一个重要分支,正日益成为理论与算法软件开发的前沿阵地。它不仅模拟了生物体通过试错与环境交互进行学习的基本模式,更在游戏博弈、机器人控制、自动驾驶、智能推荐等诸多领域展现出巨大潜力。本文将系统性地探讨强化学习的核心理论与关键算法,并阐述其在软件开发实践中的重要性。
强化学习的核心理论框架
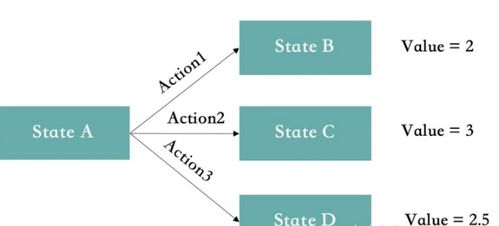
强化学习的理论基础建立在马尔可夫决策过程(Markov Decision Process, MDP)之上。MDP为描述顺序决策问题提供了一个严谨的数学模型,它由五个关键要素构成:状态集(S)、动作集(A)、状态转移概率(P)、奖励函数(R)和折扣因子(γ)。智能体(Agent)的目标,是在这个框架内,通过与环境的持续交互,学习到一个最优的策略(Policy),即从状态到动作的映射规则,以期最大化长期累积奖励的期望值。
这一理论框架引出了两个核心概念:价值函数和策略优化。价值函数用于评估在特定状态下(或采取特定动作后)的长期价值,分为状态价值函数和动作价值函数。贝尔曼方程则构成了价值迭代和策略优化的数学基础,揭示了当前价值与未来价值之间的递归关系。
经典算法演进:从动态规划到深度强化学习
强化学习的算法发展路径,清晰地体现了从理论模型到工程实践的演进。
- 基于动态规划的经典方法:在模型已知(即P和R已知)的情况下,策略迭代和价值迭代等算法可以精确求解最优策略。它们是理解强化学习原理的基石,但在模型未知或状态空间巨大的实际问题中直接应用受限。
- 蒙特卡洛方法与时序差分学习:为了在模型未知的环境下学习,蒙特卡洛方法通过完整的经验轨迹来估计价值函数,而时序差分(TD)学习,特别是著名的Q-learning和Sarsa算法,则通过“自举”的方式,利用当前估计值更新下一时刻的估计值,实现了更高效的单步在线学习。Q-learning(一种离策略算法)因其简单有效,成为早期应用中最流行的算法之一。
- 函数逼近与深度强化学习的革命:当面对高维、连续的状态或动作空间时,传统的表格型方法遭遇存储和泛化瓶颈。引入函数逼近器(如线性模型、神经网络)来拟合价值函数或策略,是必然选择。深度强化学习(Deep RL)将深度神经网络与强化学习相结合,取得了里程碑式的突破。
- 深度Q网络(DQN):通过经验回放和目标网络两大核心技术,稳定了深度网络在Q-learning中的应用,在Atari游戏上达到甚至超越了人类水平。
- 策略梯度方法:直接参数化并优化策略。REINFORCE算法是其早期代表,而后续的Actor-Critic框架将价值函数(Critic)与策略(Actor)结合,降低了方差,提升了学习效率,如A2C、A3C、TRPO和PPO等算法,已成为当前复杂连续控制任务的主流选择。
算法软件开发:挑战与工程实践
将强化学习理论转化为稳定、高效的软件系统,面临着独特挑战,也驱动着算法开发工具的进步。
- 算法实现复杂性:RL算法涉及采样、训练、评估等多个循环,且对超参数(如学习率、折扣因子、探索率)极为敏感。代码实现需要高度的模块化和清晰的抽象。
- 环境交互与仿真:一个标准化、高效的环境接口是开发的基础。OpenAI Gym、DeepMind Control Suite等平台提供了丰富的基准测试环境,极大地促进了算法研发与比较。
- 样本效率与训练稳定性:RL通常需要海量的交互数据,且训练过程可能不稳定。工程上需要集成经验回放、分布式采样、课程学习、以及细致的监控与调试工具(如TensorBoard、WandB)来应对这些挑战。
- 从仿真到现实(Sim2Real)的鸿沟:在仿真中训练的策略迁移到物理世界时,常因模型不精确而失效。领域随机化、系统辨识等算法与工程技术的结合,是解决此问题的关键。
未来展望
强化学习的理论和算法仍在快速发展中。研究方向包括但不限于:提升样本效率与泛化能力的元学习、探索与利用的更好平衡、多智能体强化学习的协同与竞争、以及将世界模型与规划更深度地融合的模型基强化学习。对软件开发而言,构建更强大、易用的开源框架(如Stable-Baselines3, Ray RLlib),降低研究与工程应用的门槛,将是推动整个领域进步的重要力量。
总而言之,强化学习是一门连接人工智能理论、算法创新与复杂系统软件开发的桥梁学科。掌握其从MDP理论基础到深度RL算法,再到工程化实现的完整知识体系,对于开发下一代具有自主决策能力的智能系统至关重要。